What is Stratified sampling and why should you use it (with example in Python)?
The random sampling is a fundamental process in statistics and machine learning. The random sampling can be performed as simple random sampling or as stratified sampling based on the input dataset and goal of downstream analysis.
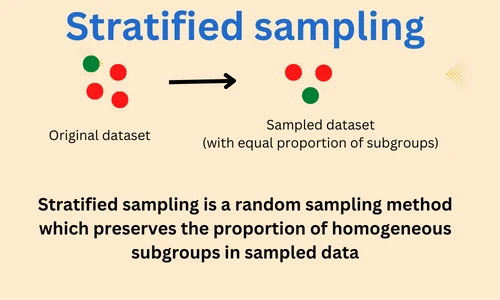
Stratified sampling is a random sampling method where heterogeneous datasets (dataset containing multiple groups) are sampled such that the proportions of groups are similar between the original and sampled dataset.
The stratified sampling involves two steps,
- the heterogeneous groups are separated into homogenous groups (also known as strata),
- samples are drawn randomly and proportionally from each homogenous group.

As compared to simple random sampling, stratified sampling preserves the proportion of each group. Therefore, stratified sampling is advantageous for datasets where groups distribution is unequal i.e., some observations in some groups are high in number than those in other groups.
Stratified sampling vs cluster sampling: Stratified sampling should not be confused with cluster sampling as both involve groups in the population. Cluster sampling differs from stratified sampling in that it samples entire clusters (groups) rather than individual observations.
Example of Stratified sampling
For example, a breast cancer dataset contains the 9 clinical features of 116 patients. Among them, 64 (55%) patients are diagnosed with breast cancer, and remaining 42 (45%) are healthy (imbalanced dataset for target classes).
If we perform simple random sampling for splitting the training and testing datasets for fitting the machine learning model, it is very likely that the training dataset may not equally represent the observations of cancer and healthy patients, and the resulting model may not have good performance.
When the datasets are imbalanced, stratified sampling is an effective way to split the training and testing datasets since it samples cancer and healthy patients proportionally in the training and testing datasets.
Now, perform the stratified sampling on breast cancer dataset to select the training dataset (80% samples from original dataset),
import pandas as pd
df=pd.read_csv("https://reneshbedre.github.io/assets/posts/ml/cancer_data.csv")
df.head(2)

The breast cancer datasets contain 9 clinical features and one response variable (target variable). The target variable
Classifcations contains the two classes viz. healthy patients (labeled as 1) and cancer patients (labeled as 2).
Check the distribution of two classes in percentages,
df['Classification'].value_counts(normalize=True)*100

The target class distribution suggests that breast cancer datasets have imbalanced distribution for two classes (higher cancer patients than healthy patients).
If we perform simple random sampling to get the training dataset (such as 80% of the original dataset), it is highly likely that more number of cancer patients data will be selected. This is not ideal for fitting the machine learning model.
In this case, stratified sampling is useful as it will proportionally draw the samples i.e. the proportion will be similar to that of the original dataset.
Perform the stratified sampling to select the 80% training dataset,
# group by Classification and perform simple random sampling on each group
stratified = df.groupby('Classification').apply(lambda x: x.sample(frac=0.8)).droplevel(0)
stratified['Classification'].value_counts(normalize=True)*100

You can see that the proportion of cancer and healthy patients are similar in the stratified sample as compared to that of the original breast cancer dataset.
Read my article on how to perform the stratified sampling using train_test_split() function from the scikit-learn
package
References
- Patrício, M., Pereira, J., Crisóstomo, J., Matafome, P., Gomes, M., Seiça, R., & Caramelo, F. (2018). Using Resistin, glucose, age and BMI to predict the presence of breast cancer. BMC Cancer, 18(1).
Enhance your skills with courses on machine learning
- Advanced Learning Algorithms
- Machine Learning Specialization
- Machine Learning with Python
- Machine Learning for Data Analysis
- Supervised Machine Learning: Regression and Classification
- Unsupervised Learning, Recommenders, Reinforcement Learning
- Deep Learning Specialization
- AI For Everyone
- AI in Healthcare Specialization
- Cluster Analysis in Data Mining
This work is licensed under a Creative Commons Attribution 4.0 International License
Some of the links on this page may be affiliate links, which means we may get an affiliate commission on a valid purchase. The retailer will pay the commission at no additional cost to you.

