How to identify and drop duplicates based on single and multiple columns in a pandas DataFrame
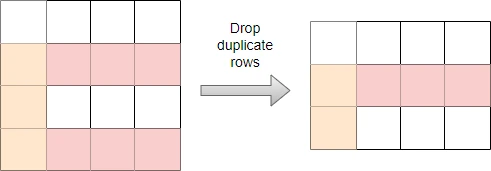
In this article, you will learn how to identify and drop duplicates in a pandas Dataframe and Series. Let’s first create random Pandas DataFrame (you can also import pandas DataFrame from file).
import pandas as pd
# Create DataFrame
df = pd.DataFrame({ 'col1':[10, 11, 25, 10],
'col2':[2, 3, 25, 2],
'col3': ['A', 'B', 'B', 'A']})
df
# output
col1 col2 col3
0 10 2 A
1 11 3 B
2 25 25 B
3 10 2 A
Drop duplicate rows based on all columns
You can use the pandas drop_duplicates() function to drop the duplicate rows based on all columns. You can either keep
the first or last occurrence of duplicate rows or completely drop the duplicate rows.
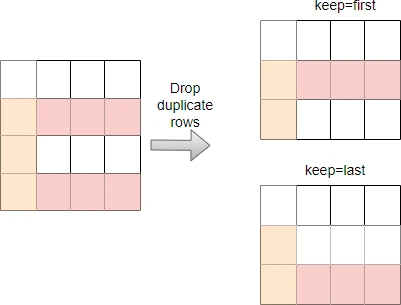
For example, drop duplicate rows and keep the first occurrence,
df.drop_duplicates() # same as df.drop_duplicates(keep='first')
# output
col1 col2 col3
0 10 2 A
1 11 3 B
2 25 25 B
If you want to keep the last occurrence, pass the keep='last' parameter,
df.drop_duplicates(keep='last')
# output
col1 col2 col3
1 11 3 B
2 25 25 B
3 10 2 A
If you want to drop duplicate rows entirely (without keeping any occurrence), you can pass keep='False' parameter,

df.drop_duplicates(keep=False)
# output
col1 col2 col3
1 11 3 B
2 25 25 B
As you see in the above example, the duplicated rows were entirely dropped without keeping any occurrence
Drop duplicate rows based on specific columns
By default, the drop_duplicates() function drop duplicates rows based on all columns. If you want to drop duplicate rows
based on specific columns, pass the subset=['column_names'] parameter
For example, drop duplicate rows based on col3 (you can also pass keep parameter to the keep the preferred row),
df.drop_duplicates(subset='col3')
# output
col1 col2 col3
0 10 2 A
1 11 3 B
Drop duplicate rows based on multiples columns e.g. col1 and col3 (you can also pass keep parameter to keep the preferred row),
df.drop_duplicates(subset=['col1', 'col3'])
# output
col1 col2 col3
0 10 2 A
1 11 3 B
2 25 25 B
Drop duplicate rows and update DataFrame
If you want to update the current DataFrame by dropping the duplicate rows, you can pass the inplace=True parameter,
For example, if you want to drop the duplicated rows and simultaneously update the DataFrame,
df.drop_duplicates(inplace=True)
df
# output
col1 col2 col3
0 10 2 A
1 11 3 B
2 25 25 B
Drop duplicate from pandas Series
You can also use the drop_duplicates()
function to drop duplicated values in pandas Series. The other parameters of drop_duplicates() such as keep and
inplace also apply to the pandas series
# create pandas series
dfs = pd.Series(['A', 'B', 'B', 'C', 'D'])
dfs.drop_duplicates()
# output
0 A
1 B
3 C
4 D
dtype: object
Identifying duplicate rows
You can use pandas duplicated() function to identify the duplicated rows as boolean values series (True if duplicated)
For example, identify duplicated rows based on all columns in the DataFrame,
df.duplicated()
# output
0 False
1 False
2 False
3 True
dtype: bool
The last row of the DataFrame is duplicated as it returns True
Now, identify duplicated rows based on specific columns in the DataFrame,
df.duplicated(subset='col3')
# output
0 False
1 False
2 True
3 True
dtype: bool
# get duplicated rows
df.loc[df.duplicated(subset='col3')]
# output
col1 col2 col3
2 25 25 B
3 10 2 A
In addition, you can also pass the keep parameter to identify the first or last occurrences of the duplicated rows in a DataFrame,
For example, identify the first occurrence of duplicated rows,
df.duplicated(keep='last')
# output
0 True
1 False
2 False
3 False
dtype: bool
Counting duplicated rows in pandas DataFrame
You can also count the duplicated rows in pandas DataFrame based on the duplicated value in single or multiple columns
Count duplicated rows based on all columns,
df.duplicated().sum()
# output
1
The one row is duplicated based on all columns in a DataFrame
Count duplicated rows based on specific columns,
df.duplicated(subset='col3').sum()
# output
2
The two rows are duplicated based on col3 values in a DataFrame
Summary
In this article, you learned how to use pandas drop_duplicates() and duplicated() functions to identify and drop
duplicated rows in DataFrame and Series. In addition, you also learned how to identfiy and count the duplicated rows in
a DataFrame.
Enhance your skills with courses on Python and pandas
- Python for Data Analysis: Pandas & NumPy
- Mastering Data Analysis with Pandas: Learning Path Part 1
- Data Analysis Using Python
- Python for Everybody Specialization
- Python for Data Science, AI & Development
- Python 3 Programming Specialization
If you have any questions, comments or recommendations, please email me at reneshbe@gmail.com
This work is licensed under a Creative Commons Attribution 4.0 International License
Some of the links on this page may be affiliate links, which means we may get an affiliate commission on a valid purchase. The retailer will pay the commission at no additional cost to you.

